

Skip to content material
Claude’s defective “recognized entity” neurons someday override its “do not reply” circuitry.
Which of these bins represents the “I do not know” a part of Claude’s digital “mind”?
Credit score:
Getty Photos
Probably the most irritating issues about utilizing a big language mannequin is coping with its tendency to confabulate data, hallucinating solutions that aren’t supported by its coaching knowledge. From a human perspective, it may be onerous to know why these fashions do not merely say “I do not know” as an alternative of creating up some plausible-sounding nonsense.
Now, new analysis from Anthropic is exposing not less than a few of the interior neural community “circuitry” that helps an LLM determine when to take a stab at a (maybe hallucinated) response versus when to refuse a solution within the first place. Whereas human understanding of this inner LLM “resolution” course of remains to be tough, this sort of analysis might result in higher general options for the AI confabulation drawback.
When a “recognized entity” is not
In a groundbreaking paper final Might, Anthropic used a system of sparse auto-encoders to assist illuminate the teams of synthetic neurons which are activated when the Claude LLM encounters inner ideas starting from “Golden Gate Bridge” to “programming errors” (Anthropic calls these groupings “options,” as we are going to within the the rest of this piece). Anthropic’s newly revealed analysis this week expands on that earlier work by tracing how these options can have an effect on different neuron teams that signify computational resolution “circuits” Claude follows in crafting its response.
In a pair of papers, Anthropic goes into nice element on how a partial examination of a few of these inner neuron circuits supplies new perception into how Claude “thinks” in a number of languages, how it may be fooled by sure jailbreak methods, and even whether or not its ballyhooed “chain of thought” explanations are correct. However the part describing Claude’s “entity recognition and hallucination” course of supplied one of the crucial detailed explanations of a sophisticated drawback that we have seen.
At their core, giant language fashions are designed to take a string of textual content and predict the textual content that’s more likely to observe—a design that has led some to deride the entire endeavor as “glorified auto-complete.” That core design is beneficial when the immediate textual content carefully matches the sorts of issues already present in a mannequin’s copious coaching knowledge. Nonetheless, for “comparatively obscure details or matters,” this tendency towards at all times finishing the immediate “incentivizes fashions to guess believable completions for blocks of textual content,” Anthropic writes in its new analysis.
Tremendous-tuning helps mitigate this drawback, guiding the mannequin to behave as a useful assistant and to refuse to finish a immediate when its associated coaching knowledge is sparse. That fine-tuning course of creates distinct units of synthetic neurons that researchers can see activating when Claude encounters the identify of a “recognized entity” (e.g., “Michael Jordan”) or an “unfamiliar identify” (e.g., “Michael Batkin”) in a immediate.
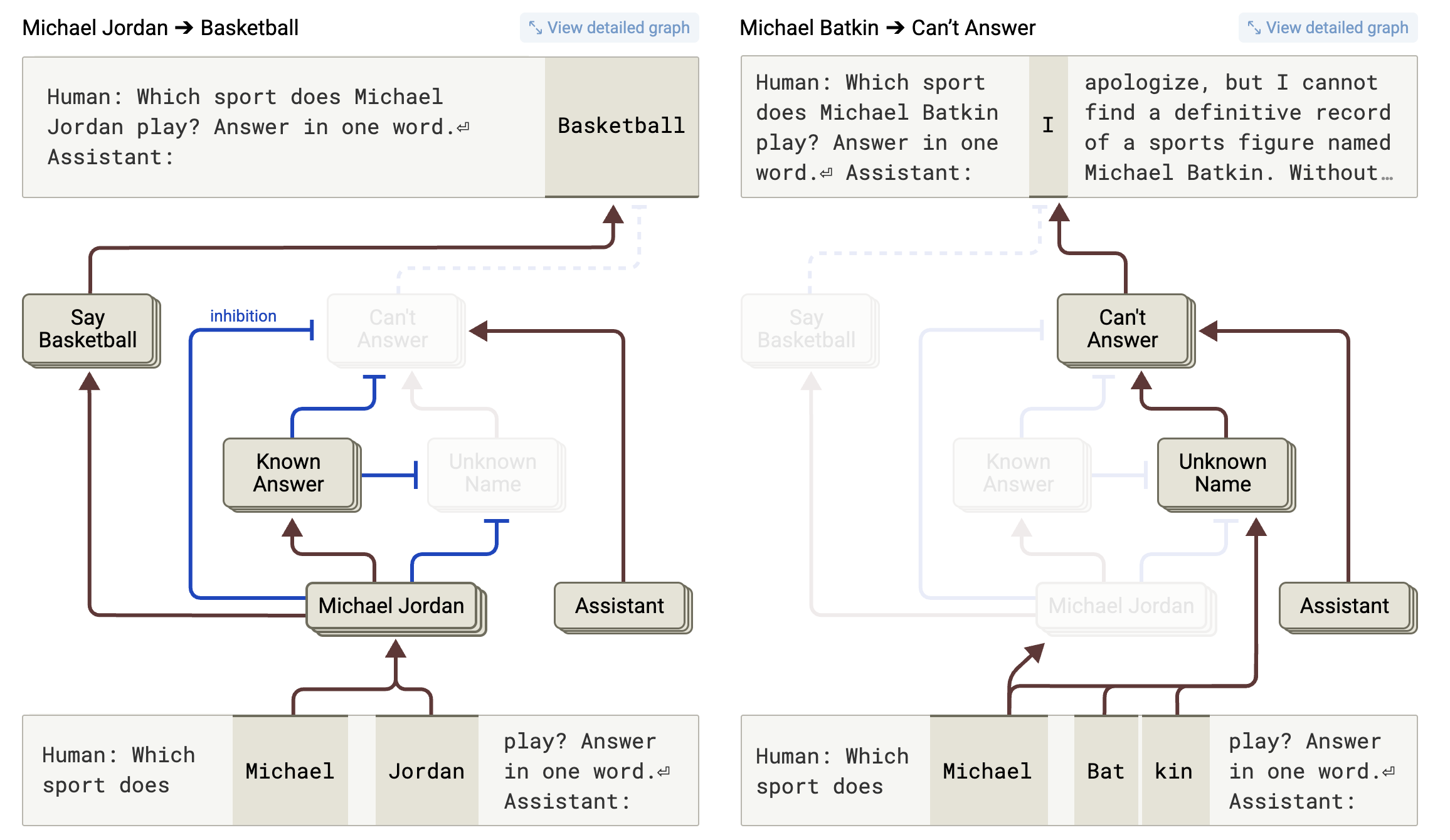
A simplified graph exhibiting how varied options and circuits work together in prompts about sports activities stars, actual and faux.
A simplified graph exhibiting how varied options and circuits work together in prompts about sports activities stars, actual and faux.
Credit score:
Anthropic
Activating the “unfamiliar identify” characteristic amid an LLM’s neurons tends to advertise an inner “cannot reply” circuit within the mannequin, the researchers write, encouraging it to supply a response beginning alongside the traces of “I apologize, however I can not…” Actually, the researchers discovered that the “cannot reply” circuit tends to default to the “on” place within the fine-tuned “assistant” model of the Claude mannequin, making the mannequin reluctant to reply a query until different energetic options in its neural web counsel that it ought to.
That is what occurs when the mannequin encounters a widely known time period like “Michael Jordan” in a immediate, activating that “recognized entity” characteristic and in flip inflicting the neurons within the “cannot reply” circuit to be “inactive or extra weakly energetic,” the researchers write. As soon as that occurs, the mannequin can dive deeper into its graph of Michael Jordan-related options to supply its finest guess at a solution to a query like “What sport does Michael Jordan play?”
Recognition vs. recall
Anthropic’s analysis discovered that artificially growing the neurons’ weights within the “recognized reply” characteristic might power Claude to confidently hallucinate details about utterly made-up athletes like “Michael Batkin.” That type of outcome leads the researchers to counsel that “not less than some” of Claude’s hallucinations are associated to a “misfire” of the circuit inhibiting that “cannot reply” pathway—that’s, conditions the place the “recognized entity” characteristic (or others prefer it) is activated even when the token is not really well-represented within the coaching knowledge.
Sadly, Claude’s modeling of what it is aware of and does not know is not at all times significantly fine-grained or lower and dried. In one other instance, researchers word that asking Claude to call a paper written by AI researcher Andrej Karpathy causes the mannequin to confabulate the plausible-sounding however utterly made-up paper title “ImageNet Classification with Deep Convolutional Neural Networks.” Asking the identical query about Anthropic mathematician Josh Batson, then again, causes Claude to reply that it “can not confidently identify a particular paper… with out verifying the data.”

Artificially suppressing Claude’s the “recognized reply” neurons forestall it from hallucinating made-up papers by AI researcher Andrej Karpathy.
Artificially suppressing Claude’s the “recognized reply” neurons forestall it from hallucinating made-up papers by AI researcher Andrej Karpathy.
Credit score:
Anthropic
After experimenting with characteristic weights, the Anthropic researchers theorize that the Karpathy hallucination could also be induced as a result of the mannequin not less than acknowledges Karpathy’s identify, activating sure “recognized reply/entity” options within the mannequin. These options then inhibit the mannequin’s default “do not reply” circuit regardless that the mannequin does not have extra particular data on the names of Karpathy’s papers (which the mannequin then duly guesses at after it has dedicated to answering in any respect). A mannequin fine-tuned to have extra strong and particular units of those sorts of “recognized entity” options may then have the ability to higher distinguish when it ought to and should not be assured in its potential to reply.
This and different analysis into the low-level operation of LLMs supplies some essential context for the way and why fashions present the sorts of solutions they do. However Anthropic warns that its present investigatory course of nonetheless “solely captures a fraction of the overall computation carried out by Claude” and requires “just a few hours of human effort” to know the circuits and options concerned in even a brief immediate “with tens of phrases.” Hopefully, that is simply step one into extra highly effective analysis strategies that may present even deeper perception into LLMs’ confabulation drawback and perhaps, someday, how you can repair it.

Kyle Orland has been the Senior Gaming Editor at Ars Technica since 2012, writing primarily concerning the enterprise, tech, and tradition behind video video games. He has journalism and pc science levels from College of Maryland. He as soon as wrote an entire e book about Minesweeper.
19 Feedback

{kind=link}